MoDex: A Diffusion Policy for Sequential Multi-Object Dexterous Grasping
Abstract
This work addresses the problem of sequentially grasping multiple objects with a single dexterous gripper without releasing previously grasped objects, a task that has been limited to approaches requiring known object models or poses. The proposed solution, MoDex, overcomes these constraints by training an opposition-space and point-cloud-conditioned diffusion policy to output the next gripper pose. The opposition space condition specifies which robotic fingers participate in each grasp, allowing the gripper to use only a subset of available degrees of freedom while preserving the remaining degrees of freedom for subsequent grasps. To ensure MoDex is sim-to-real transfer-ready, we propose atwo-step training process: first, the policy is pre-trained via imitation learning onexpert demonstrations, followed by reinforcement learning fine-tuning to furtherenhance robustness. MoDex is evaluated against state-of-the-art baselines on a MuJoCo-simulated Franka Panda robot equipped with an Allegro Hand, and in the real world using the same hardware. The experimental results demonstratethat MoDex consistently outperforms existing learning-based methods, achieving4.75-36.25% and 6.67-17.78% higher success rates in simulation and real experiments, respectively.
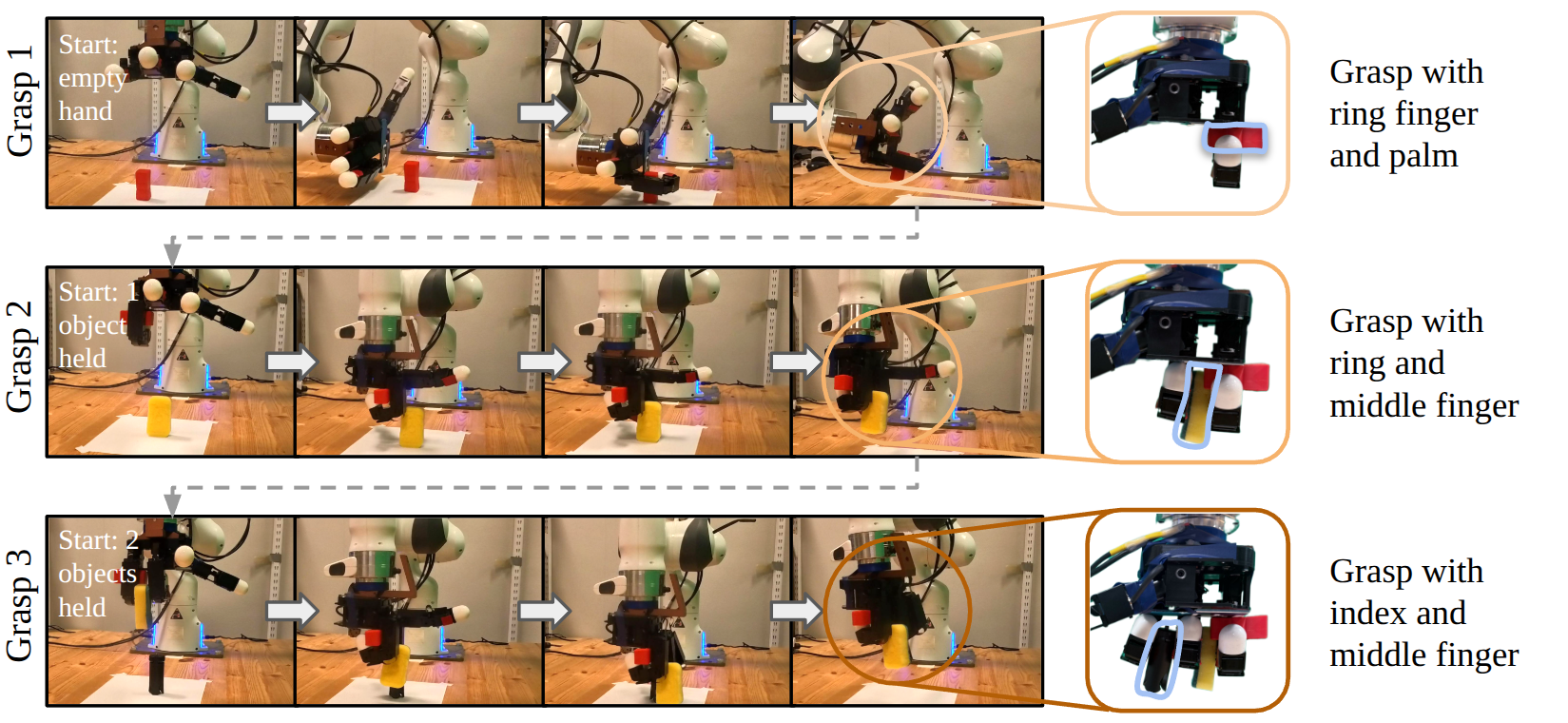
MoDex sequentially picks three objects with a single dexterous hand, securely holding all previously grasped objects while picking the next one. All grasps are produced by a single policy. Dashed arrows link the end of one grasp to the start of the next; close-ups (right) show the final hand configuration after each.
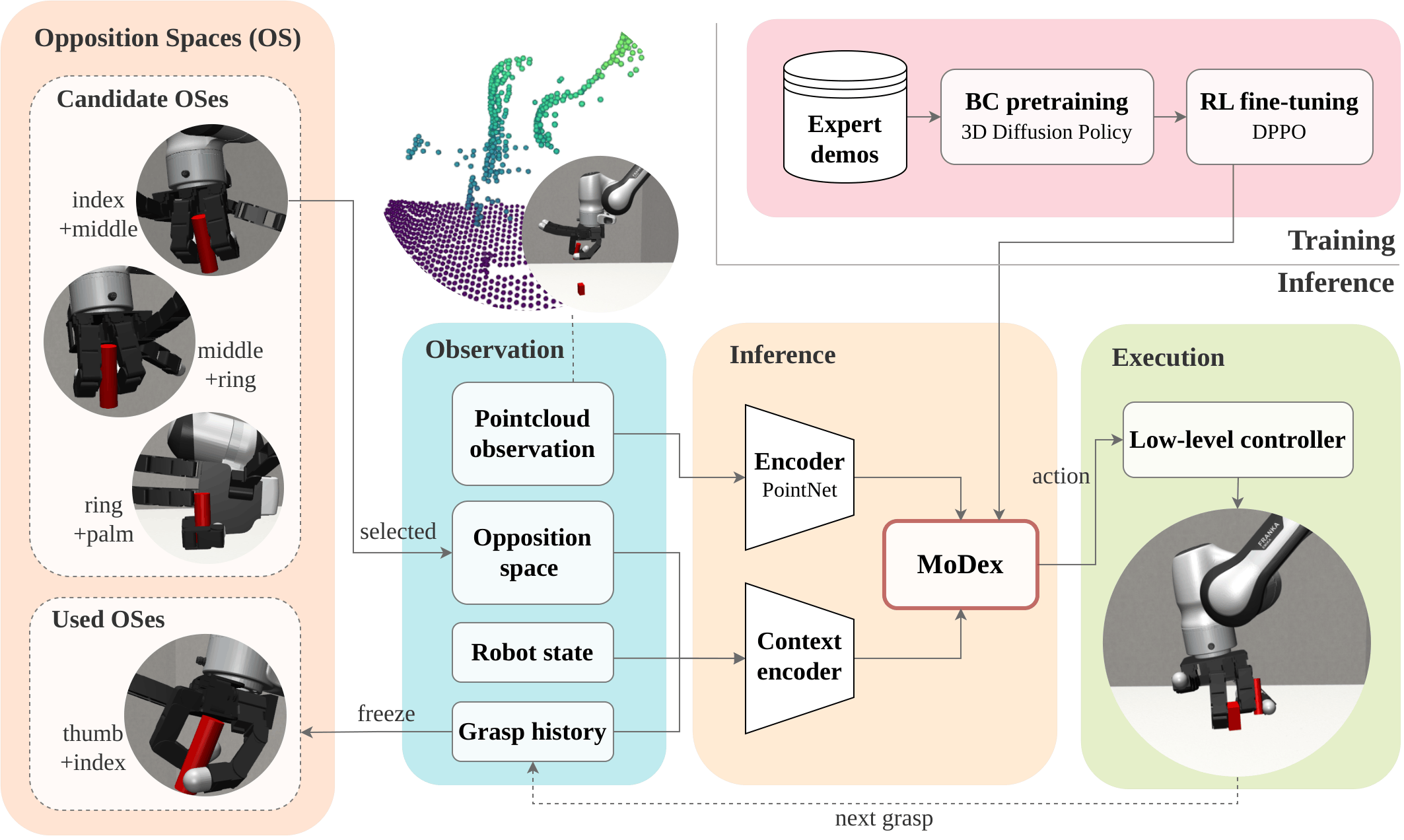
Method overview. MoDex maps an observation, including a point cloud, the commanded OS, the robot state, and the grasp history of OSes already used, to the next grasp action. A PointNet encoder and a context encoder feed the diffusion policy. The executed grasp is appended to the history before the next object. Training (top right): the policy is first pre-trained by behavior cloning on expert demonstrations (DP3), then RL fine-tuned with DPPO.
Experimental Results
MoDex achieves the best simulation performance across all grasp stages and transfers to real hardware after training only in simulation.
Simulation Success Rates (%)
| Method | Stage 1 | Stage 2 | Stage 3 | Average |
|---|---|---|---|---|
| BC-RNN | 52.50 | 13.75 | 26.25 | 30.83 |
| PPO | 0.00 | 0.00 | 0.00 | 0.00 |
| SeqDiffuser | 1.67 | 0.00 | 0.00 | 0.56 |
| MoDex-BC | 60.00 | 46.25 | 41.25 | 49.17 |
| MoDex (Ours) | 70.00 | 50.00 | 55.00 | 58.33 |
Ablation Study Success Rates (%)
| Variant | Stage 1 | Stage 2 | Stage 3 |
|---|---|---|---|
| DP3 (full) | 60.00 | 46.25 | 41.25 |
| w/o Grasp History Context | 70.00 | 3.75 | 38.75 |
| MoDex (full) | 70.00 | 50.00 | 55.00 |
| DPPO w/o grasp reward | 67.50 | 45.00 | 45.00 |
| DPPO w/o maintain reward | 66.25 | 46.25 | 41.50 |
Real-World Success Rates (%)
| Method | Stage 1 | Stage 2 | Stage 3 |
|---|---|---|---|
| MoDex-BC | 40.00 | 20.00 | 6.67 |
| MoDex | 57.78 | 26.67 | 20.00 |
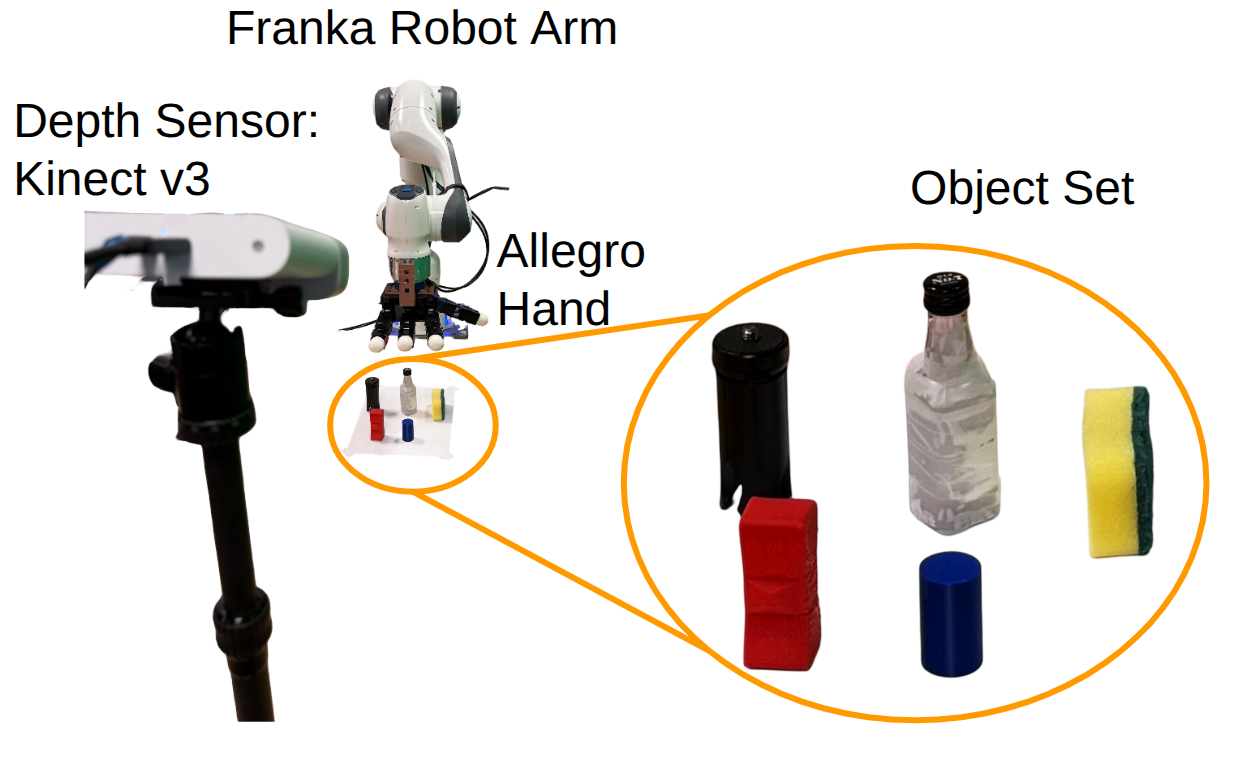
Additional Figures

BibTeX
@article{modex,
title={MoDex: A Diffusion Policy for Sequential Multi-Object Dexterous Grasping},
author={Authors},
journal={Conference/Journal Name},
year={2026},
}